

我是萬萬沒想到,就在西方還沉浸在聖誕假期,瘋狂⠢€œ⠩Ž年⠢€⠧š„時候,咱們中國企業給人家放了個新年二踢腳,給人家腦瓜子崩得嗡嗡得。
前有宇樹科技的機器狗視頻讓大家驚呼,還要啥波士頓動力。

緊接著又來了個國產大模型 DeepSeek,甚至有股做空英偉達的味道。
具體咋回事兒,咱給你嘮明白咯。
前幾天,⠄eepSeek⠥‰›剛公布最新版本⠖3⠯„,與大洋彼岸那個自稱 Open ,卻越來越 Close 的公司產品不同,這個 V3 是開源的。
不過開源還不是他最重要的標簽,⠄eepSeek-V3⠯ 以下簡稱⠖3⠯‚„兼具了性能國際一流,技術力牛逼,價格擊穿地心三個特點,這一套不解釋連招打得業內大模型廠商們都有點暈頭轉向了。

⠖3 一發布, OpenAI 創始成員 Karpathy 直接看嗨了,甚至發出了靈魂提問,難道說大模型們壓根不需要大規模顯卡集群?
我估計老黃看到這頭皮都得發麻了吧。

同時, Meta 的 AI 技術官也是直呼 DeepSeek 的成果偉大。
知名 AI 評測博主 Tim Dettmers ,直接吹起來了,表示 DeepSeek 的處理優雅⠢€œelegant”⠣€‚
而在這些技術出身的人,看著 V3 的成績送去讚揚的時候,也有些人急了。
⠦悥姧‰𑩂㨪Œ複製比較簡單啦,很難不讓人覺得他在內涵 DeepSeek 。

更有意思的是,做到這些的公司既不是什麽大廠,也不是純血 AI 廠商。
DeepSeek 公司中文名叫深度求索,他們本來和 AI 沒任何關係。
就在大模型爆火之前,他們其實是私募機構幻方量化的一個團隊。

而深度求索能夠實現彎道超車,既有點必然,也好像有點運氣的意思。
早在 2019 年,幻方就投資 2 億元搭建了自研深度學習訓練平台⠢€œ⠨ž⧁먟€號⠢€⠯ˆ† 2021 年已經買了足足 1 萬丈英偉達 A100⠩ᯥ᧚„算力儲備了。

要知道,這個時候大模型沒火,萬卡集群的概念更是還沒出現。
而正是憑借這部分硬件儲備,幻方才拿到了 AI 大模型的入場券,最終卷出了現在的 V3 。
你說好好的一個量化投資領域的大廠,幹嘛要跑來搞 AI 呢?
深度求索的 CEO 梁文鋒在接受采訪的時候給大家聊過,並不是什麽看中 AI 前景。
⠨€Œ是在他們看來,⠢€œ⠩€š用人工智能可能是下一個最難的事之一⠢€⠯𐍤€‘來說,⠢€œ⠩€™是一個怎麽做的問題,而不是為什麽做的問題。⠢€⠀

就是抱著這麽股⠢€œ⠨Ž𝂠”⠥‹,深度求索才搞出了這次的大新聞,下麵給大家具體講講 V3 有啥特別的地方。
首先就是性能強悍,目前來看,在 V3 麵前,開源模型幾乎沒一個能打的。
⠩‚„記得去年年中,小紮的⠍eta⠦Ž襇ᥞ‹⠌lama 3.1⠯•𖦙‚就因為性能優秀而且開源,一時間被捧上神壇,結果在⠖3⠦‰‹裏,基本是全麵落敗。
而在各種大廠手裏的閉源模型,那些大家耳熟能詳的什麽 GPT-4o 、 Claude 3.5 Sonnet 啥的, V3 也能打得有來有回。
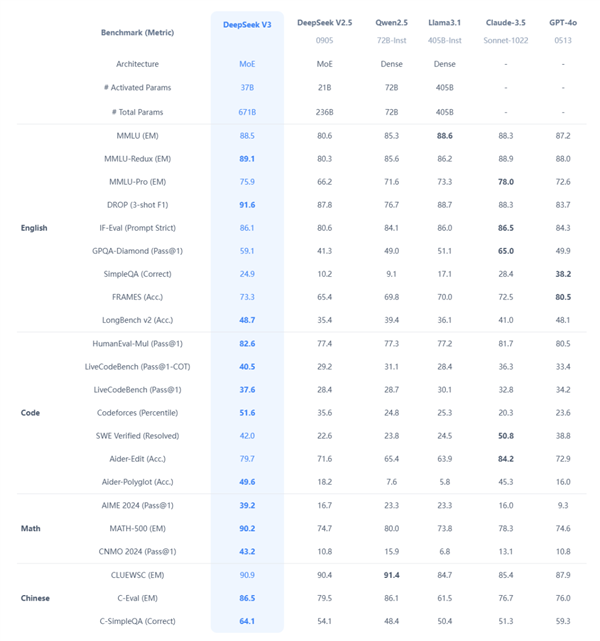
你看到這,可能覺得不過如此,也就是追上了國際領先水平嘛,值得這麽吹嗎?
殘暴的還在後麵。
大家大概都知道了,現在的大模型就是一個通過大量算力,讓模型吃各種數據的煉丹過程。
在這個煉丹期,需要的是大量算力和時間往裏砸。
所以在圈子裏有了一個新的計量單位⠢€œGPU 時⠢€⠯˜倫褺†多少塊 GPU 花了多少個小時的訓練時間。

GPU 時越高,意味著花費的時間、金錢成本就越高,反之就物美價廉了。
前麵說的此前開源模型王者, Llama 3.1 405B ,訓練周期花費了 3080⠨젇PU 時。
可性能更強的 V3 ,隻花了不到 280⠨젇PU 時。
以錢來換算, DeepSeek 搞出 V3 版本,大概隻花了 4000⠥䚨줺‘幣。
而 Llama 3.1 405B 的訓練期間, Meta 光是在老黃那買了 16000⠥䚥€‹ GPU ,保守估計至少都花了十幾億人民幣。
⠨‡楤–的那幾家閉源模型,動輒都是幾十億上百億大撒幣的。

你別以為 DeepSeek 靠的是什麽歪門邪道,人家是正兒八經的有技術傍身的。
為了搞清楚 DeepSeek 的技術咋樣,咱們特地聯係了語核科技創始人兼 CTO 池光耀,他們主力發展企業向的 agent 數字人,早就是 DeepSeek 的鐵粉了。
池光耀告訴我們,這次⠖3⠧š„更新主要是⠳⠥€‹方麵的優化,分別是通信和顯存優化、推理專家的負載均衡以及FP8⠦𗷥ˆ精度訓練。
各個部分怎麽實現的咱也就不多說了,總體來說,大的整體結構沒啥變化,更多的像是咱們搞基建的那一套傳統藝能,把工程做得更高效、更合理了。
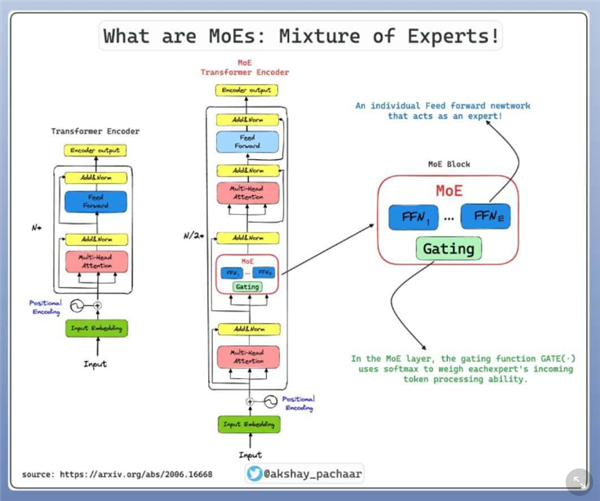
首先,⠖3⠩€š過通信和顯存優化,極大幅度減少了資源空閑率,提升了利用效率。
而推理專家(⠥…𗥂™推理能力的 AI 係統或算法,能夠通過數據分析得出結論⠯š„負載均衡就更巧妙了,一般的大模型,每次啟動,必須把所有專家都等比例放進工位(⠩ᯥ혂 ),但真正回答用戶問題時,十幾個專家裏麵隻用到一兩個,剩下的專家占著工位(⠩ᯥ혂 )摸魚,也幹不了別的事情。
⠨€Œ⠄eepSeek⠦ŠŠ專家分成熱門和冷門兩種,熱門的專家,複製一份放進顯存,處理熱門問題;冷門的專家也不摸魚,總是能被分配到問題。
FP8 混合精度訓練則是在之前被很多團隊嚐試無果的方向上拓展了新的一步,通過降低訓練精度以降低訓練時算力開銷,但卻神奇地保持了回答質量基本不變。
也正是這些技術上的革新,才得到了大模型圈的一致好評。

通過一直以來的技術更新迭代, DeepSeek 收獲的回報也是相當驚人的。
他們 V3 版本推出後,他們的價格已經是低到百萬次幾毛錢、幾塊錢。
他們甚至還在搞了個新品促銷活動,到明年 2 月 8 號之前,在原來低價的基礎上再打折。
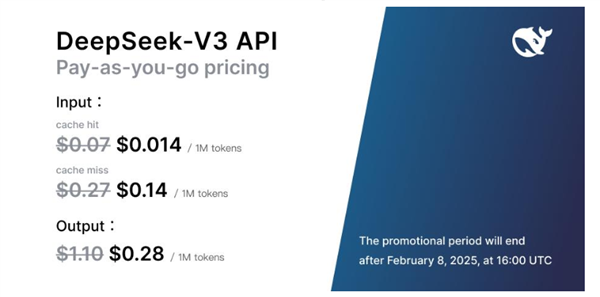
而一開始提到同樣開源的 Claude 3.5 Sonnet ,每百萬輸入輸出,至少都得要幾十塊以上。。。
更要命的是,這對 DeepSeek 來說已經是常規套路了。
早在去年初,DeepSeek V2⠦补ž‹發布後,就靠著一手低價,被大家叫做了AI⠧•Œ拚多多。
他們還進一步引發了國內大模型公司的價格戰,諸如智譜、字節、阿裏、百度、騰訊等大廠紛紛降價。

池光耀也告訴我們,他們公司早在去年 6 、 7 月份就開始用上了 DeepSeek ,當時也有國內其他一些大模型廠商來找過他們。
⠤𝆥’Œ⠄eepSeek⠥ƒ多的,模型⠢€œ⠥ˆ太笨了,跟⠄eepSeek⠤𘍥œ褸€個維度⠢€⠯悦žœ模型能力和 DeepSeek 差不多,那個價格⠢€œ⠥Ÿ쩃𝦘10⠥€以上⠢€⠣€‚
更誇張的是,由於技術⠢€œ⠩™遙領先⠢€⠥š„降本增效,哪怕⠄eepSeek⠨€™麽便宜,根據他們創始人梁文峰所說,他們公司還是賺錢的。。。是不是有種隔壁比亞迪搞 998 ,照樣財報飄紅的味道了。
不過對於我們普通用戶來說, DeepSeek 似乎也有點偏門了。
因為他的強項主要是在推理、數學、代碼方向,而多模態和一些娛樂化的領域不是他們的長處。

而且眼下,盡管 DeepSeek 說自己還是賺錢的,但他們團隊上上下下都有股極客味,所以他們的商業化比起其他廠商就有點弱了。
但不管怎麽說, DeepSeek 的成功也證明了,在 AI 這個賽道還存在的更多的可能。
按以前的理解,想玩轉 AI 後麵沒有個金主爸爸砸錢買顯卡,壓根就玩不轉。
但現在看起來,掌握了算力並不一定就是掌握了一切。
我們不妨期待下未來,更多的優化出現,讓更多的小公司、初創企業都能進入 AI 領域,差評君總感覺,那才是真正的 AI 浪潮才對。
还没有评论,来说两句吧...